Big Data
June 25, 2014
Tiempo total: 0 días con 2:47:40 hrs
Es una de las herramientas más utilizadas tanto en los negocios como en el área de tecnología de información (IT) porque el objetivo que se tiene con su análisis es la extracción de los datos más valiosos de las grandes cantidades de información.

Qué es?
Son sistemas que manipulan grandes cantidades de información, es decir que es el conjunto de datos que superan la capacidad habitual de tiempo en que un software puede manipular, editar y procesar la información.
Gigabyte = 1,073,741,824 bytes
Terabyte = 1,099,511,627,776 bytes
Petabyte = 1,125,899,910,000,000,000,000,000,000,000,000,000,000,000,000 bytes
Exabyte = 1,152,921,500,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000 bytes
Big Data es la información estructurada, no estructurada y semi-estructurada que no puede analizarse utilizando bases de datos relacionales, y para su correcto procesamiento se deben de utilizar sistemas completamente orientados a la manipulación de petabytes y exabytes. Toda esta información es generada a partir de todas las aplicaciones y dispositivos que se encargan de recolectar información de dispositivos móviles, fotos, videos, sistemas GPS, sensores digitales en equipo industrial, automóviles, medidores eléctricos, veletas que se encargan de reunir información de posicionamiento, movimiento, vibración, temperatura, humedad, cambios físicos en el aire entre otros.

Que no hace Big Data
En la actualidad se puede hacer una relación entre lo que es big data y la paradoja de los ciegos y el elefante, consiste en que cada uno cree saber que es de acuerdo a lo que saben pero la realidad del concepto es otro.
- No puede hacer que un negocio sea exitoso.
- No hace resta importancia a los data warehouses y a las técnicas de bussiness intelligence.
- No todas las personas lo están implementando.
Desafortunadamente, Big data ofrece grandes oportunidades pero son pocas las empresas las que lo logran implementar.

Cuatro aspectos importantes
- Cantidad: El volumen de información que los sistemas Big data deben de manipular debido al constante incremento de la información.
- Velocidad: La alta velocidad con que la información se debe de procesar.
- Variedad: Los distintos tipos de estructuras que se deberán de manipular.
- Veracidad: Consiste en que la información debe de ser validad – y es bastante importante – debido a que es utilizada para la toma de decisiones.
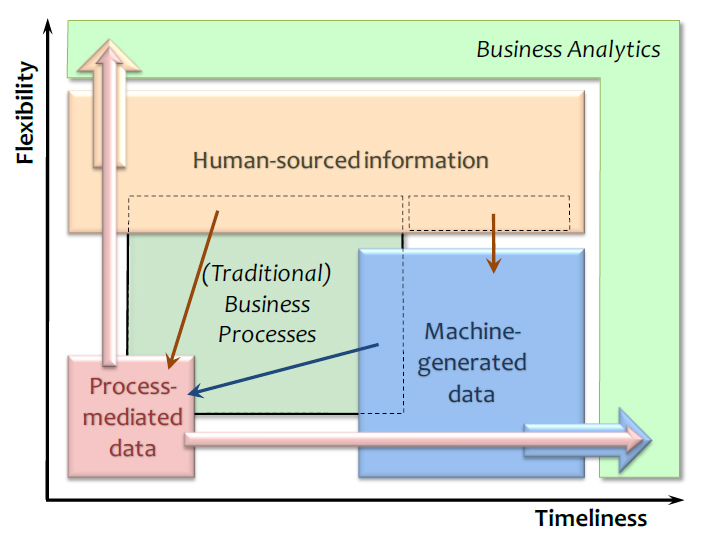
Dominios de información
- Social (Human sourced information): Información que tiene como origen las actividades de las personas, estas son imágenes, videos y texto que describen las experiencias de cada persona. Esta información proviene de distintos medios, como dispositivos móviles, computadoras, GPS y demás dispositivos que digitalizan cada experiencia – Desde Tweets hasta comentarios de películas, o inclusive películas.
- Negocio (Process mediated data): Todas las empresas generan información que provienen de sus transacciones y consiste en los intereses de los clientes, facturas, compras, pago de servicios entre otros.
- Maquinaria (Machine generated data): Llamada también m2m o maquina a máquina. Esto quiere decir que la información de las empresas no únicamente son transacciones o facturas, también se puede mencionar la información generada a partir de las maquinas que se encargan de realizar tareas de automatización, por ejemplo la información de sensores o complejos registros de computadoras.
Se puede mencionar que si en un día se reúne toda la información creada por los dispositivos móviles, por los datos de censo de la población, registros médicos, impuestos, análisis de redes sociales, si se juntara toda la información creada se obtendría alrededor de 2.5 quintillones de bytes diarios:
1 quintillón = 1,000,000,000,000,000,000,000,000,000,000 bytes
Una de las razones es el movimiento constante de datos en el mundo: Facebook genera alrededor de 100 Petabytes de fotos y videos, mientras Twitter cerca de 12 Terabytes de información diarios.
Plataforma integrada para la información
Los orígenes de big data se centran en las grandes empresas como Google y Yahoo! Que analizaron el problema de la gran cantidad de información que debían manipular, valiéndose de ingenieros que aprovecharon las herramientas de software libre disponibles para crear una solución.
- Core business data: es la información de más valor de la empresa y se representa por bases de datos relacionales, como DB2 que es la base de la tecnología.
- Core reporting and analytic data: Es la información de reporte y análisis, en términos de tecnología también puede mencionarse un modelo relacional y DW. Algunos ejemplos del software utilizado en este pilar son: IBM InfoSphere Warehouse, IBM Smart Ana-lytics System y el nuevo IBM PureData System for Operational Analytics. En este pilar los negocios necesitan el procesamiento de grandes cantidades de información utilizando MPP (procesamiento masivo paralelo).
- Deep analytic information: Requiere el procesamiento de información de manera flexible utilizando la tecnología Hadoop, este último es un sistema orientado al procesamiento de sistemas big data, que se describirá más adelante.
- Fast analytic data: Este pilar requiere del análisis rápido de la información que proviene de las distintas fuentes de información.
- Specialty analytic data: Este pilar requiere el análisis de la información a través de bases de datos como No-SQL y aparece dos veces en la grafica para mostrar el análisis requerido en ambos dominios de información.
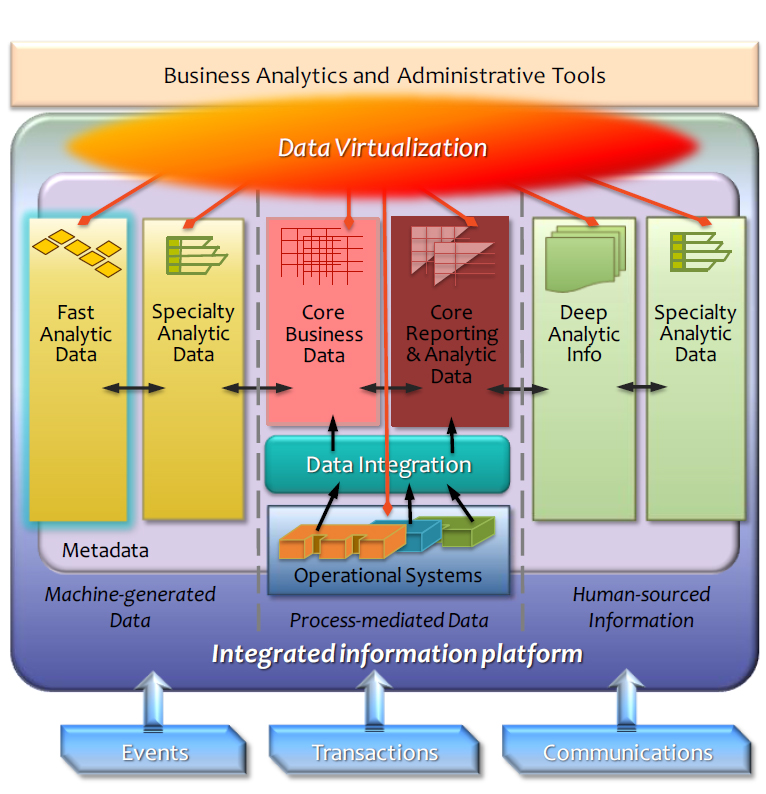
La virtualización de la información permite a los usuarios finales el acceso hacia la misma desde distintos medios, mostrando una vista orientada a los negocios a partir de todas las fuentes de información.
Hadoop Distributed File System
Inspirado en el proyecto de GFS y en el paradigma de programación MapReduce, el cual consiste en dividir en dos tareas para manipular los datos distribuidos a nodos de un clúster logrando un alto paralelismo en el procesamiento de información, podemos mencionar también que está totalmente orientado al manejo de grandes cantidades de información.
Proyectos relacionados con Hadoop
- Avro, ZooKeeper y Lucene: Proyectos de Apache.
- Flume: Dirige los datos de una fuente hacia otra localidad Hadoop.
- Hive: Es una infraestructura de data warehouse que facilita la administración de grandes conjuntos de datos que se encuentran almacenados en un ambiente distribuido.
- Pig: Fue desarrollado por Yahoo! para permitir a los usuarios de Hadoop enfocarse más en analizar todos los conjuntos de datos.
También podemos mencionar dos ejemplos clave de empresas importantes: Twitter y Facebook.
HBase
Es una base de datos columnar que se ejecuta en HDFS (Hadoop). HBase no soporta SQL, de hecho, HBase no es una base de datos relacional. Facebook utiliza HBase en su plataforma desde Noviembre del 2010.
Cassandra
Cassandra es una base de datos no relacional distribuida y basada en un modelo de almacenamiento de clave/valor desarrollado en Java. Permite grandes volúmenes de datos en forma distribuida. Twitter es una de las empresas que utiliza Cassandra dentro de su plataforma.
Referencias
The Big Data Zoo—Taming the Beasts
October 2012
A White Paper by
Dr. Barry Devlin, 9sight Consulting
barry@9sight.com
Paginas
[http://es.wikipedia.org/wiki/Big_data]
[http://www.ibm.com/developerworks/ssa/local/im/que-es-big-data/]
