Lucene y Spark – Apache Cassandra – Parte 3
February 3, 2018
Tiempo total: 1 días con 1:40:54 hrs
Apache Cassandra permite únicamente el operador lógico AND y no permite realizar consultas más complejas (JOIN), estas deben de resolverse mediante implementaciones de código.
Esto para el análisis de datos trae grandes consecuencias. Por ejemplo, en la siguiente instrucción queremos obtener los tweets de un usuario en dos rangos de tiempos:
SELECT * FROM tweet WHERE usuario = 502 AND year = 2018 AND month = 1 AND (timestamp > ‘2018-02-01 22:05’ AND timestamp < ‘2018-02-01 22:06’) OR (timestamp > ‘2018-02-01 22:07’ AND timestamp < ‘2018-02-01 22:08’);
Una solución muy simple es realizar dos consultas y unir los resultados (implementación con código):
SELECT * FROM tweet WHERE usuario = 502 AND year = 2018 AND month = 1 AND timestamp > ‘2018-02-01 22:05’ AND timestamp < ‘2018-02-01 22:06’;
SELECT * FROM tweet WHERE usuario = 502 AND year = 2018 AND month = 1 AND timestamp > ‘2018-02-01 22:07’ AND timestamp < ‘2018-02-01 22:08’;
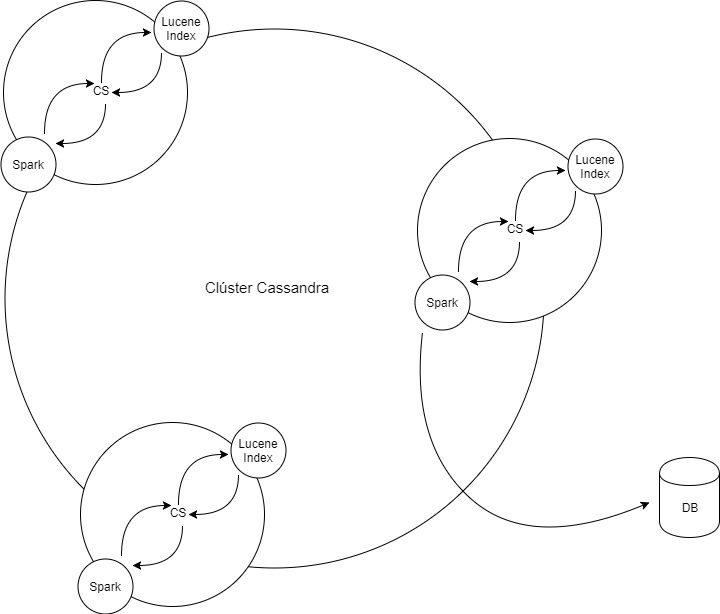
Stratio’s Cassandra Lucene Index
Es un plugin para Apache Cassandra que permite realizar consultas más complejas utilizando indexación, y por ende, obteniendo una gran optimización en el tiempo de respuesta (más del 57% según mi experiencia).
Lucene Index tiene varias características: permite realizar consultas casi instantáneamente (ElasticSearch o Solr), también permite realizar búsquedas: de texto, geoespaciales, multivariables y bitemporales.
Big data
Cuando se empiezan a almacenar grandes cantidades de información, se requiere una gran capacidad de computo para poder analizarla (obtener oro de la mina). Imagina que tienes 1 GB de distintos registros y debes poder predecir resultados o comportamientos, no sabes cuándo se necesitará esa información y sobre que rango de tiempo deberá de hacerse dicha consulta.
Para analizar esa de información (que está distribuida en todos los nodos Cassandra), la aplicación deberá de consultar el clúster Cassandra y el resultado (1 GB de registros) almacenarlo en su memoria, luego se analizarían los registros.
Te imaginas cuanto tiempo tardará este proceso? al hacer la consulta a Cassandra, cada nodo deberá de analizar sus registros en búsqueda de coincidencias, los resultados de la búsqueda deberán de viajar por la red hacia el servidor de aplicaciones, quien deberá de computar 1GB de información.

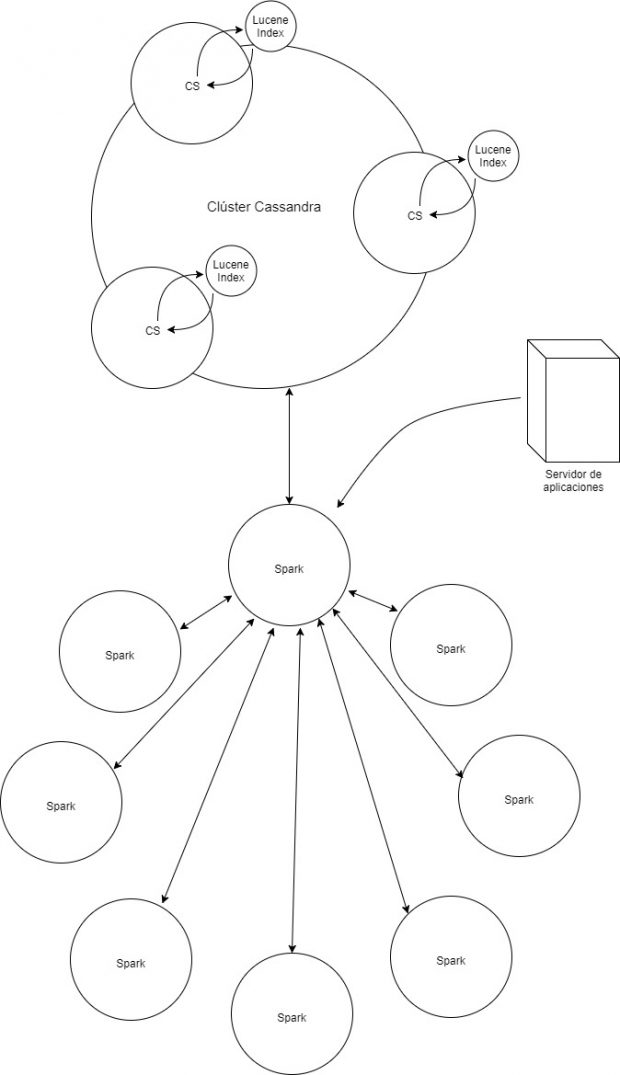
Apache Spark es sinónimo de cómputo distribuido (un cluster de nodos Spark), una de las principales tendencias de Big data (procesamiento de grandes cantidades de información).
Implementar Spark y Cassandra consumirá muchas horas de estudio, hay distintas arquitecturas para hacerlo. La primera será instalar una instancia Spark por cada nodo Cassandra, de esta forma se analizará la información en tiempo real y la podrás almacenar en una base de datos externa (bueno, esto lo puedes hacer con cualquier lenguaje de programación).
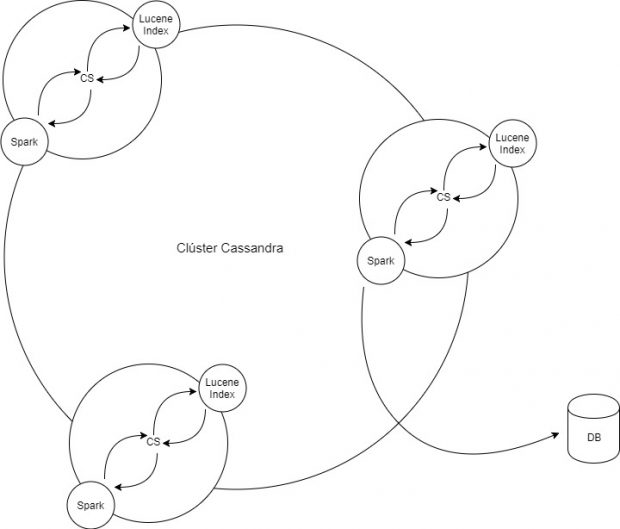
La otra forma, es crear dos clústers: Cassandra y Spark. La velocidad de los resultados dependerá de la cantidad y capacidad de los nodos Spark, al mismo tiempo dependerá de la velocidad en que se pueden transmitir los datos en la red de clústers.
Video
Al igual que el video de la parte 1, este video te explica lo necesario para poder abstraer el concepto sobre Spark:
Referencias
Las imágenes de esta publicación fueron creadas con Draw.io
[https://www.draw.io/]
[https://github.com/Stratio/cassandra-lucene-index/blob/branch-3.0.14/README.rst]
[https://es.wikipedia.org/wiki/Elasticsearch]
[https://es.wikipedia.org/wiki/Apache_Solr]
[https://en.wikipedia.org/wiki/Bitemporal_Modeling]
[https://www.youtube.com/watch?v=fBWLzB0FMX4]
[https://deepdataocean.ai/images/Spark.png]
